阻碍你使用 GraphQL 的十个问题
在最近半年中,LeetCode 的一些新功能已经开始尝试使用 GraphQL。如果你在 LeetCode 网站中查看一下开发者工具中收集到的请求,也许会发现一个与众不同的请求 POST https://leetcode.com/graphql/。是的,要是你想给 LeetCode 写些爬虫的话,可得好好研究一下我们在这个 Endpoint 下挂载了哪些数据。
我在使用 GraphQL 的过程中经历了理解、误解、再理解的过程。作为吃了 GraphQL 这个螃蟹的人,希望能够通过这篇文章更好地帮助各位读者理解 GraphQL 是什么,GraphQL 会给你带来什么,以及将 GraphQL 应用于你的系统中需要注意哪些问题。这不是一篇系统的科普文,如果你有什么其他疑问可以评论中留言询问。
以下内容皆为作者个人理解,如果错误,欢迎讨论指出。我会随时修正,拜谢!
1. 什么是 GraphQL?
从官方的定义来说,GraphQL 是一种针对 API 的查询语言;在我看来,GraphQL 是一种标准,而与标准相对的便是实现。就像 EcmaScript 与 JavaScript 的关系,从一开始你就需要有这样一种认知:GraphQL 只定义了这种查询语言语法如何、具体的语句如何执行等。但是,你在真正使用某种 GraphQL 的服务端实现时,是有可能发现 GraphQL 标准中所描述的特性尚未被实现;或者这种 GraphQL 的实现扩展了 GraphQL 标准所定义的内容。
举例来说,就像 ES 2017 标准正式纳入了 async/await,而从实现的角度上说,IE 没有实现这一标准,而 Edge 16 和 Chrome 62 则实现了这一标准(数据来源于 caniuse)说回 GraphQL 标准,与之相对的有相当多的服务器端实现。他们的大多遵循 GraphQL 标准来实现,但也可能稍有差别,这一切需要你自己去探索。
2. 如何从零入门 GraphQL?
- 先看标准:https://graphql.org/ (纯 GraphQL,与任何什么 JavaScript, Python 都无关)
- 再看服务端实现:到 https://graphql.org/code/ 里找到跟你的服务端技术有关的实现
- 再看客户端实现:Relay 或 appollo-client, etc.
- 学习使用 DataLoader 来获取列表数据
3. GraphQL 与 RESTful 有什么区别?
首先放上一张来自于 graphql.org 的图片。REST 与 GraphQL 都是服务端所承载的系统对外的服务接口,因此两者肯定是可以共存的,甚至可以共用一套 Authorization 等业务逻辑。
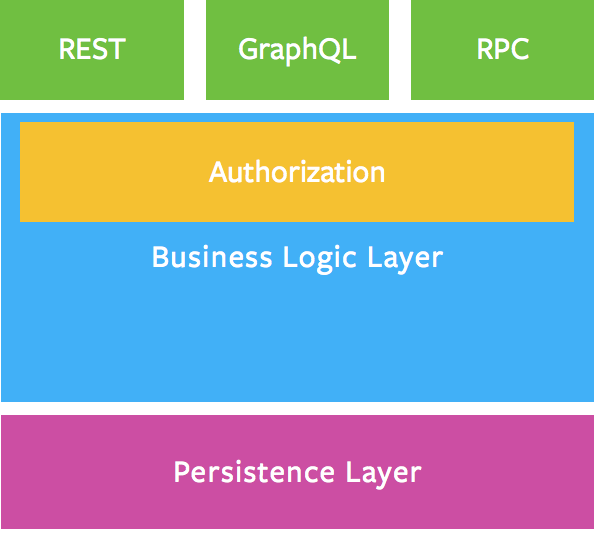
那么 GraphQL 与 RESTful 的具体区别有什么呢?我觉得主要是两点。
1. 入口 (entry point)
RESTful 的核心理念在于资源 (resource),且讲究一个 RESTful 接口仅操作单一资源;因此在你使用 RESTful 时,会设计出大量的接口。GraphQL 是单一入口,一般配置在 [host]/graphql/,所有的资源都从该入口通过 graphql 的语句获取或修改(当然 GraphQL 亦支持多入口,但显然多入口的数量也远小于 RESTful)。
2. 数据的关联性
RESTful 所操作的资源相对是离散的;而 GraphQL 的数据更有整体性。
举个例子,如果要获取 A 的朋友的朋友,用 RESTful 该怎么做呢?
假设我们有这样一个接口:
GET /user/:userId/friends/而 A 有 20 个好朋友,那么我们总共需要发送 20 + 1 = 21 次 REST 请求。
或者我们为了这种特殊场景设计出以下接口:
GET /user/:userId/friendsAndHisFriends/emmmmm… 虽然看起来很别扭,但是只需要一次请求呢!
那么在 GraphQL 中,怎么做呢?
首先我们需要给 User 定义 Schema (GraphQL 有一套完整的类型系统):
type User {
id: ID!
name: String!
friends: [User]
}假设我们在 Graph root 上只挂了一个 Node,叫 user:
type Query {
user(id: ID!): User
}那么我们从客户端发送的 query 就可以写成这样:
query ($userId: ID) {
user(id: $userId) {
name
friends {
name
friends {
name
}
}
}
}最后这一个请求就搞定查询朋友的朋友这个蛋疼的需求啦!机智的你肯定已经发现了:这个 query 是不是可以无限循环地写下去?你想的没错,确实可以这么干!在 GraphQL 的官网上是这么形容自己的:
It’s Graphs All the Way Down *
它就像是一颗无限向下延伸的树。所以在我看来,GraphQL 更应该叫 TreeQL,当然在图论里,Tree 就是 Graph 也没毛病啦。需要注意的是,这也会引出 “N + 1 problem” 的话题——naive 的 GraphQL 服务端实现会让这段 query 变得异常慢!
怎么解决这个棘手的问题?心急的小伙伴请跳转到 6.1 N+1 问题!
4. GraphQL 能做到修改数据吗?
看了上面的 query 的例子,你肯定很好奇,graphql 这种看上去好像只为查询而存在的语言,是不是有办法做到修改数据呢?
答案是:能。
仅仅为了使得 GraphQL 这个 data platform 变得更加完整,GraphQL 标准中加入了一种操作符,名为 mutation。因为我觉得这种设计确实比较一般,此处就不举例了,详情见:https://graphql.org/learn/queries/#mutations
5. GraphQL 与 RESTful 相比有什么优点?
1. 数据的关联性和结构化更好
这一点已经在本文的第 3 个问题中有所描述。
2. 更易于前端缓存数据
这个一般像 Relay 和 apollo-client 都替你做好了,如果你想了解它的缓存原理,请移步 GraphQL Caching
3. Versionless API
相比于 RESTful 为了兼容新老客户端所添加的版本号,在 GraphQL 中,如果你需要服务端提供与以前不一样的行为,只需要修改 root Query 的定义,在上面额外添加你想要的 Node 即可。
4. 更健壮的接口
不用再因为在缺乏沟通的情况下修改接口,而为系统埋下不稳定的定时炸弹。一切面向前端的接口都有强类型的 Schema 做保证,且完整类型定义因 introspection 完全对前端可见,一旦前端发送的 query 与 Schema 不符,能快速感知到产生了错误。
5. 令人期待的 subscription
如何在浏览器中接受服务端的推送信息是个老生常谈的问题。从最初的轮询,到后来的 WebSocket。如今 GraphQL 也计划引入除了 query, mutation 以外的第三种操作符 subscription,以便于直接接受服务器推送数据。在 2015 年底 GraphQL 官方发布了一篇博文:Subscriptions in GraphQL and Relay 来介绍 subscription 在他们的 iOS 和 Android App 中的应用。可惜的是相关的代码仍未开源,目前开源社区能找到的解决方案目前只有 Apollo 社区为 Node.js 写的 graphql-subscriptions。
6. GraphQL 有什么缺点?
说了 GraphQL 的那么多优点,那么它有没有缺点呢?当然也是有的。
6.1. N+1 问题
最大的问题莫过于:在实现 GraphQL 服务端接口时,很容易就能写出效率极差的代码,引起 “N+1 问题”。
什么是 N+1 问题?首先我们来举个简单的例子:
def get:
users = User.objects.all()
for user in users:
print(user.score)这是一段简单的 python 代码,使用了 Django 的 QuerySet 来从数据库抓取数据。假设我们的数据库中有两张表 User 和 UserScore 这两张表的关系如下所示:
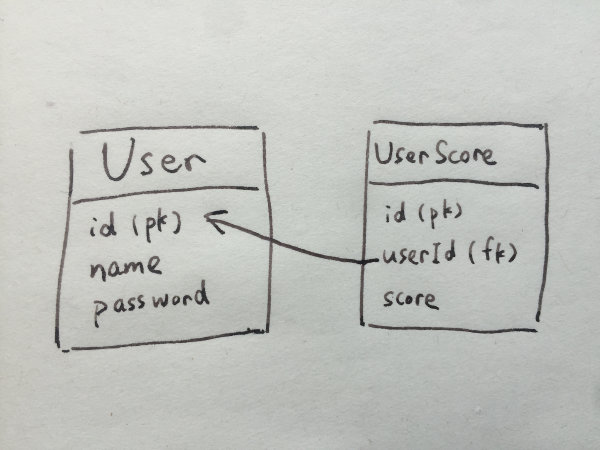
由于用户的分数并没有保存在 User 表中,又因为 QuerySet 有 lazy load 的特性,所以在 for 循环中,每一次获取 user.score 都会查一次表,最终原本 1 次数据库查询能搞定的问题,却在不恰当的实现中产生了 N+1 次对数据库的访问。
相对于 RESTful,在 GraphQL 中更加容易引起 N+1 问题。主要是由于 GraphQL query 的逐层解析方式所引起的,关于 GraphQL 如何执行 query 的细节,可以参阅 Graphql Execution。
6.2. 如何解决在 GraphQL 中的 N + 1 问题?
以下解决方案仅针对关系型数据库,如果你的项目中使用的是 NoSQL,可能解决方案有较大差别。
- 针对一对一的关系(比如我上面举例中提到的这个 User 与 UserScore 的关系),在从数据库里抓取数据时,就将所需数据 join 到一张表里。别等着 ORM 框架替你懒加载那些你需要的数据。
- 针对多对一或者多对多的关系,你就要用到一个叫做 DataLoader 的工具库了。其中,Facebook 为 Node.js 社区提供了 DataLoader 的实现。DataLoader 的主要功能是 batching & caching,可以将多次数据库查询的请求合并为一个,同时已经加载过的数据可以直接从 DataLoader 的缓存空间中获取到。这个话题要是展开说也得写一篇新的文章了,此处不多赘述。
7. 有什么可以快乐地调试 GraphQL 接口的方法?
使用 GraphiQL 可以很容易地让人感受到“代码即文档”的快乐。
8. 如何选择 GraphQL 的客户端实现?
客户端常见的框架有 Relay 和 Apollo Client。Relay 是由 Facebook 官方提供的解决方案,而 Apollo 则是在 GraphQL 方面热度超高的社区。
使用 Relay 的好处是,许多 GraphQL 的服务端框架都会支持 Relay 的标准(比如数据的分页接口)。而 apollo-client 的实现其实又在诸多方面宣称自己兼容 Relay 的风格,所以使用起来应该也是大同小异。当然笔者并没有真实地使用过 Relay,在 GraphQL 方面的经验也不够深刻,所以也不好妄下断言。
做技术选型时,同事 Ashish 说担心 Relay 太过于重量级,所以并没有决定使用 Relay。这种选择的正确性尚待考证,目前在 LeetCode 实际项目中使用了 apollo-client。
9. GraphQL 中是怎么处理分页的?
这是一个可能让 GraphQL 初学者担忧的问题,又是一个可以从官方文档中找到答案的问题。
再以找朋友为例,借用 SQL 查询中常用的筛选方法,分页接口可以设计为:
query ($userId: ID) {
user(id: $userId) {
name
friends(first: 2, offset: 3) {
name
}
}
}上面的例子意为从 $userId 的第 4 个朋友开始算起,取前 2 个朋友。
类似地,分页接口还可以设计为
friends(first: 2, after: $friendId);friends(first: 2, after: $friendCursor)
无论分页接口设计成怎么样,都需要前后端共同的封装与支持。其中 Relay 风格的分页接口在各大前后端 GraphQL 框架中基本都已有比较完整的实现。
9.1 Relay 风格的分页接口
- 参阅 Relay Cursor Connections Specification
- 注:apollo-client 兼容该分页接口
query {
user {
name
friends(first: 2, after: $cursor) {
edges {
cursor
node {
id
name
}
}
pageInfo {
hasNextPage
}
}
}
}10. GraphQL 中是怎么实现用户校验的?
你可以回看一下 3. GraphQL 与 RESTful 有什么区别 中展示的图片,答案就在其中:Authentication 属于业务逻辑层干的事情,别让 GraphQL 承担太多工作啦。
小结
鉴于网上中文的 GraphQL 资料比较有限,所以根据笔者自己的理解,总结出了此文。这十个问题可能是我入门 GraphQL 时比较关心的问题,不一定完全适用于所有人。由于篇幅所限,文中有很多细节并未展开,如果你对哪些问题想要有更深入的理解,GraphQL 官方文档是很重要的资源。此文仅作抛砖引玉之用,希望社区中能有更多关于 GraphQL 使用姿势的分享。
另外,我们 LeetCode 上海的招聘工作会在春节后全面展开,欢迎投递简历。https://leetcodechina.com/jobs/
参考文献
本文的版权归作者 邹润阳 所有,采用 Attribution-NonCommercial 3.0 License。任何人可以进行转载、分享,但不可在未经允许的情况下用于商业用途;转载请注明出处。感谢配合!